Today Prabook covers roughly 3 million biographies of people whose lives are spread over time from BC until nowadays. Along with articles written by Prabook authors, the database provides rare content collected from different biographical sources, such as international and national Who’s Who editions, biographical dictionaries, magazines, and other credible publications.

Gathering this data is a key mission of Prabook. While a part of the articles that are mostly about prominent and well-known persons are compiled by Prabook authors, a huge amount of the information originates from old biographical paper editions.

To be posted on Prabook, biographical sources should provide only factual information. This condition not only makes Prabook content more accurate and less prone to possible controversies but also protects it from copyright claims. According to both American and European law, mere collections of facts are considered unoriginal and thus not protected by copyright.
Scanned pages are processed into an array of text which is automatically refined and then processed with special text-parsing software. The parser determines the beginning and the end of each biography based on paragraphs, calculates their number and outlines them into separate articles.

At this point, a lot of other online biographical databases stop and show such digitized articles as they are. However, there is more use of information if it’s presented in a more approachable and user-friendly manner. The first obvious obstacle for that is the presence of abbreviations. “Deciphering” them not only makes the text more comprehensible but also makes its further analysis easier.
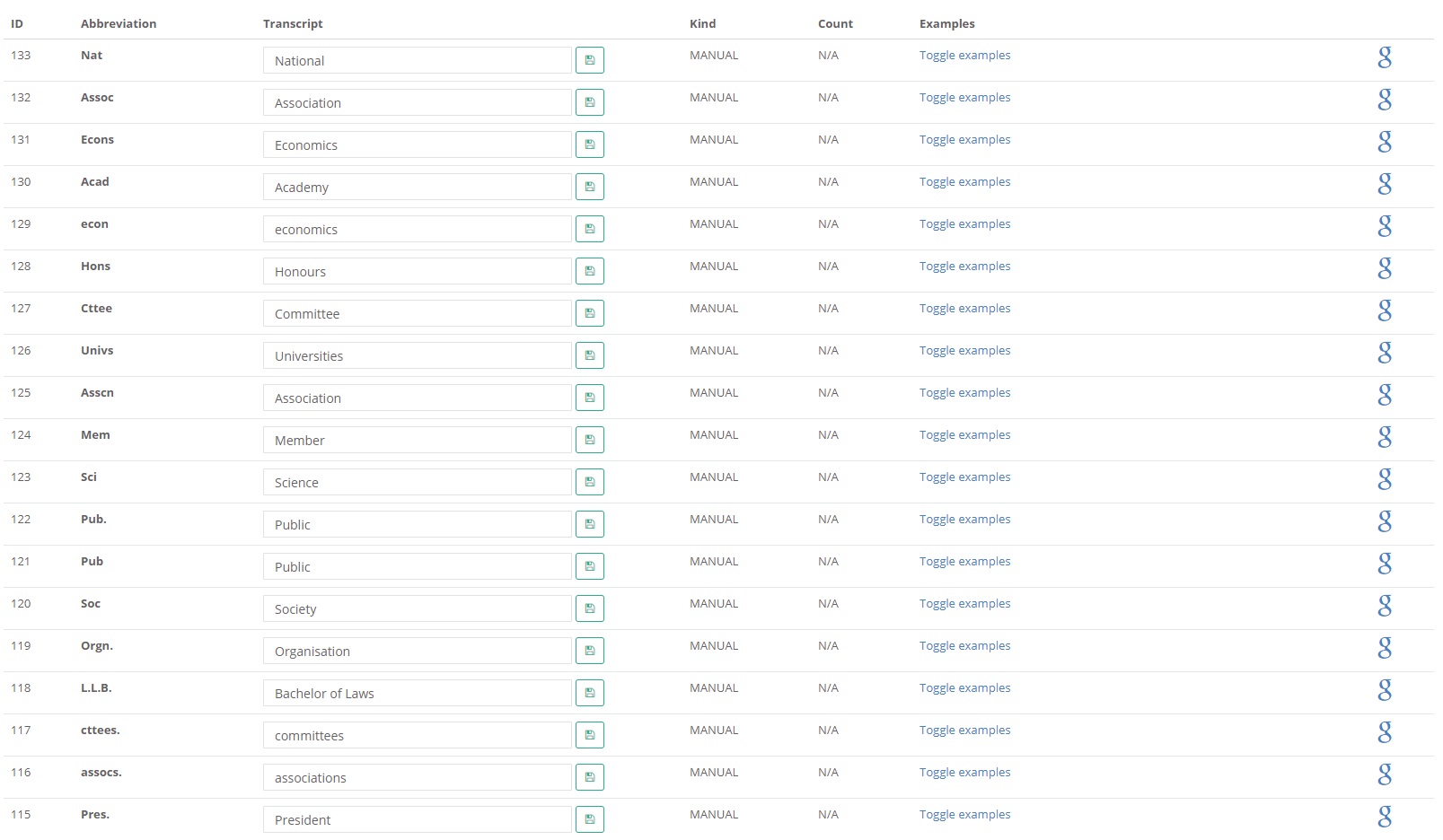
The parser then breaks the whole text of each article into sentences and analyzes them one by one, considering also their position in a given article (e.g. first paragraph, middle, bottom, etc). This program uses so-called “regular terms”, i.e. words which indicate the subject of their containing sentences. For example, the word "nationality" likely states something about the nationality of a person, especially if it's followed by another word with a capital letter (like “American” or “Nigerian”). Similarly, the word "born" listed at the beginning of a biography almost certainly indicates that the sentence which contains it tells something about the circumstances of a person's birthday. Using the dictionary of regular terms, the parser structures the text by moving each sentence into one of the database fields.
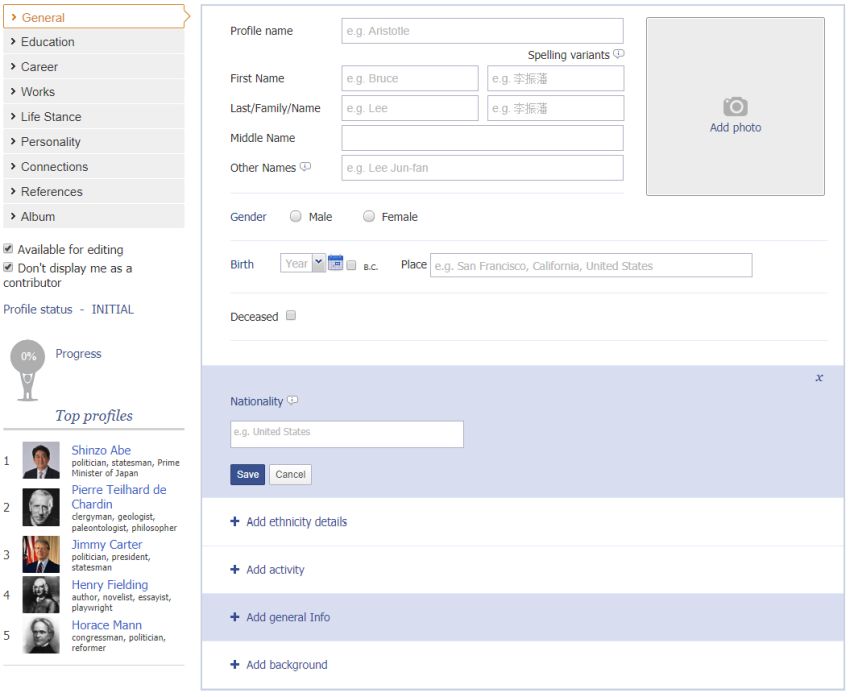
Another challenge, however, is having a database that consists of unique profiles – i.e. not having any duplicated articles. Without processing the biographical text as described above, some biographical databases often provide a list of nearly identical results on a specific search query, having their databases inflated several times with redundant articles.
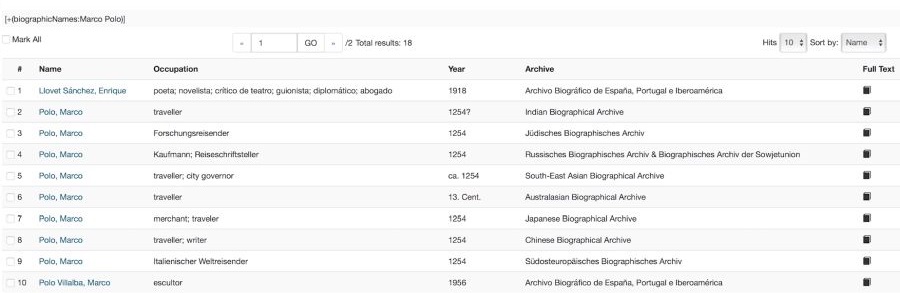
To solve this problem, we are using a merging algorithm that identifies duplicate articles based on several key fields which are “name + surname” (including their spelling variants) and date of birth as well as text similarity. As a result, unique individualized profiles that make Prabook different from other biographical online encyclopedias are obtained out of a simple array of text.

The majority of Prabook entries are created using this method. Some of the most unbeknownst biographies from old editions of worn biographical dictionaries gain new life in a form of Prabook articles due to this automatic processing.